Data Management Plan (DMP)
In newsletter No.5 “What we have accomplished so far” I already raised the topic *Data Management Plan*.
In this newsletter you find more explicit information about the central document to document your research data workflow.
The DMP is a way to document and maintain all the necessary information for understanding research data. A lot of work *can* go into it since different aspects of the research data have to be covered – what kind of data is it, where is it stored, who should have access, is there personal data involved etc.?
Intention
Think of yourself in ten years when you want to review your research data you generated and analysed within CRC1382. Will you still be able to understand the data properly or re-use it for an other research topic? Or, you are kindly asked by a colleague to share your data – will she or her be allowed to re-use it regarding the licence and rights property?
To make sure you will be able to answer all the questions and to understand your data you need to document the data generation, handling, organization and copyright status. This documentation is called Data Management Plan. It does not contain any data content but just the description of your data.
A quick and easy way to do so is to use a e.g. Word-document which will be named `README` and contains all relevant information. But think of all the projects and members of CRC1382 and what happens when every project group creates an individual `README`-file which will cover different questions and be of different information quality.
Filling out with RDMO
To make sure we at CRC1382 will document our research data in the same way and answer the same questions we need a common template. And it would be best to use an online-tool to fill out the DMP together with colleagues or others from the same project.
The tool is called “Research Data Management Organizer” (RDMO) and can be found at www.rdmo.rwth-aachen.de . The custom made DMP template for CRC1382 is available in RDMO. And your data steward already set up everything for your research project.
Let me give a quick overview about the DMP in RDMO.
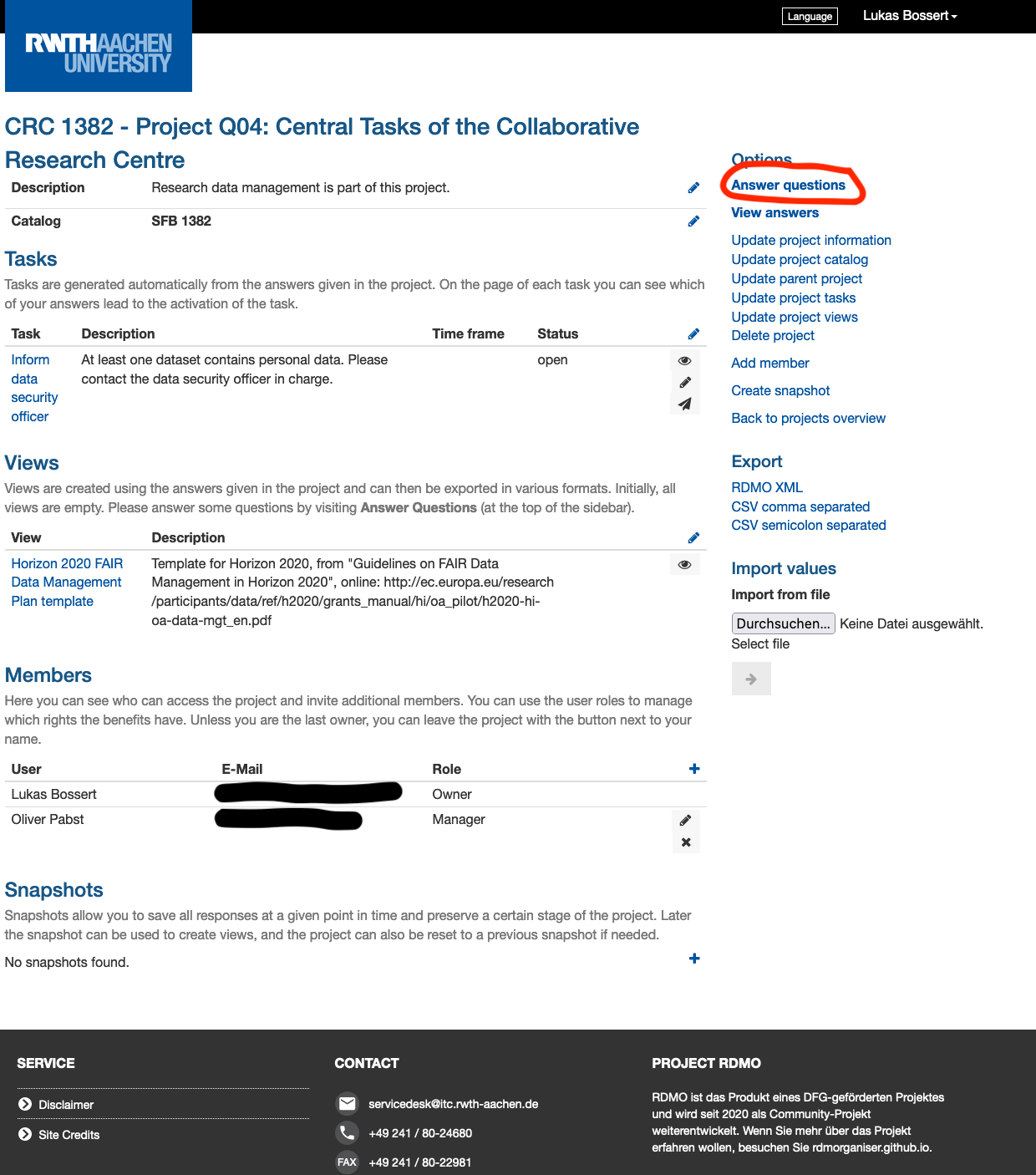
This is the project page of CRC1382 project Q04. To fill out the template simply click on Answer questions.

This is the first page of the DMP. There are always a couple of questions you can answer by pasting some already known information or checking boxes.
To save click on SAVE or SAVE AND PROCEED to go to the next page.
You find a small navigation tree in the right margin so you will always see in what section you are currently are.
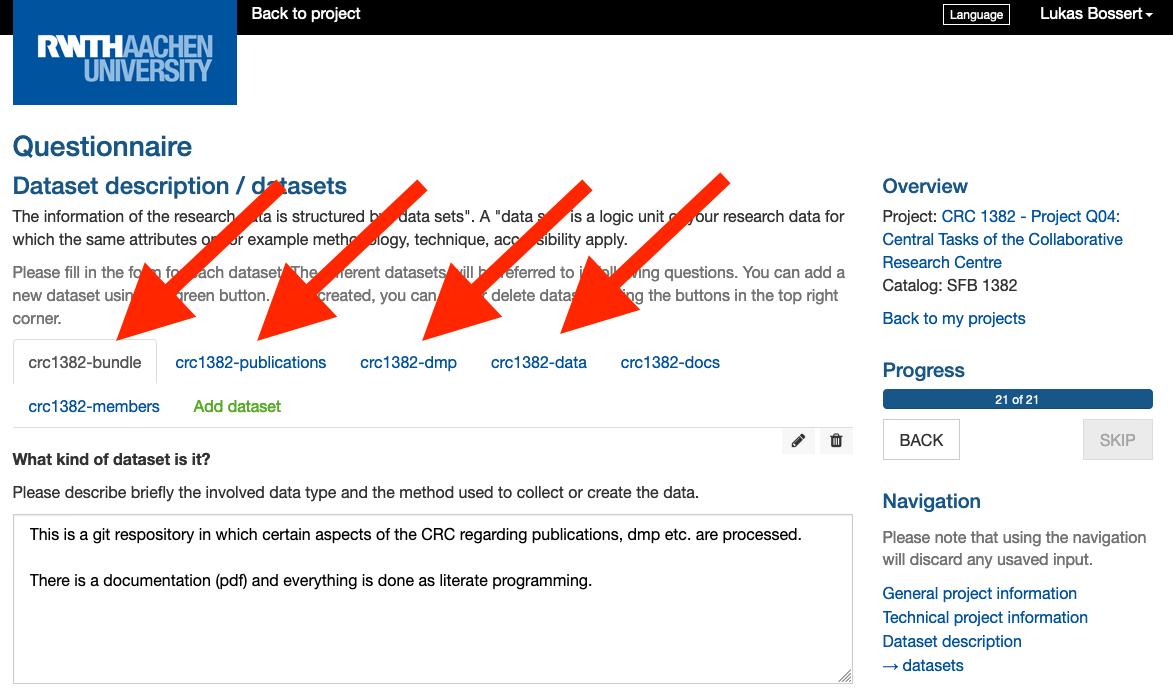
The core of the DMP template is the section called “datasets“. The definition of a dataset varies from project to project: A dataset can be all the data that comes out of a machine when you run some analysis repeatedly. On this case the data is rather homogenous and differ little. A dataset can also contain all the data that is required to tackle a research topic. In this case the data is rather heterogenous and can consist of various und multi files and formats.
You need to think about your research project and how you can define logical units regarding the research data. If you need some assistance looking at your research data and discuss logical units, please contact the data steward of CRC1382.
Maintaining
When you have answered all the questions satisfactorily you can create a snapshot on the project main page in RDMO. With a snapshot you document the status quo and make a version of the DMP that can be reviewed later.
Since the DMP is also called a “living document” you should always maintain and update it when things are changing regarding your research data and its workflow.
You can update the answers and change everything you need to by re-answering the questions as before.
Benefit
What do you have from this?
First, you will get a propper documentation of your research data and its workflow. It can be exported as PDF and look like this:

Secondly, you will meet the expectations of third party funders, e.g. DFG and ensure compliance to good data management practices.
Third (and most importantly) you will always be able to understand your data and can re-use it whenever and for whatever you want. Documentation is key.
If you like to get all about data management plan wrapped up in a quick video, have a look at the Online short-seminar of the Harvard School of Medicine.